Costco Fitness Mania: Protein bars
In a moment of extreme curiosity, I opened Costco's online portal and I looked up "protein bars". I wanted to find which one had the most protein and which one was the best bang for your buck. However, the filters of the search were not finegrained enough and I didn't feel like clicking through every item. I decided to do what any self-respecting programmer would do(\s) and that is to scrape all the protein bar results and their metadata.
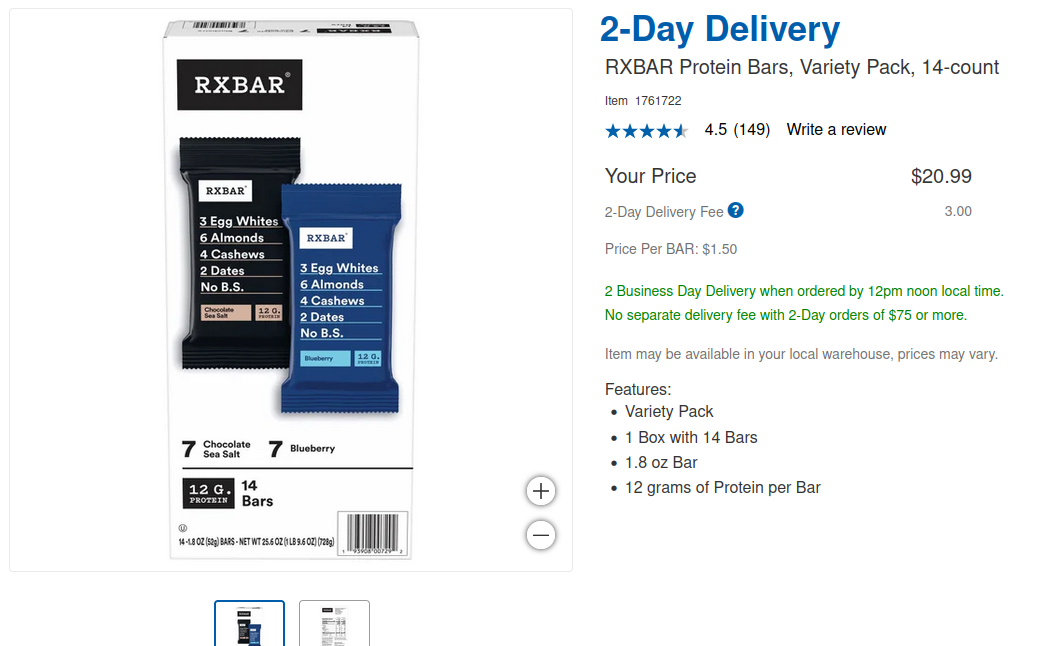
My forte is parsing web pages with Python and BeautifulSoup4 so my initial plan was to GET request the page and parse it with Python. My attempt at doing so resulted in me finding some of the many ways sites prevent scraping: parameters, headers, and cookies. I tried using wget and curl with a query like:
curl -v\
-A "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"\
-H "Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8"\
-H "Accept-Language: en-US,en;q=0.5"\
-H "Sec-Fetch-Dest: document"\
-H "Sec-Fetch-Mode: navigate"\
-H "Sec-Fetch-Site: none"\
-H "Sec-Fetch-User: ?1"\
-H "Upgrade-Insecure-Requests: 1"\
"https://www.costco.com/s?keyword=protein+bars¤tPage=1"
but the request timed out. Something was missing. I fired up Developer Console in Firefox and I went to the Networking tab. I had a hunch that with the way the Costco web app was structured, the initial page doesn't have the shopping item rendered but it's a later network call that populates the page. I opened the Response tab for the requests and I was looking for any data payload that looks like the shoppint item listings. A few items below and I saw a response that looked like the one I needed. Bingo!
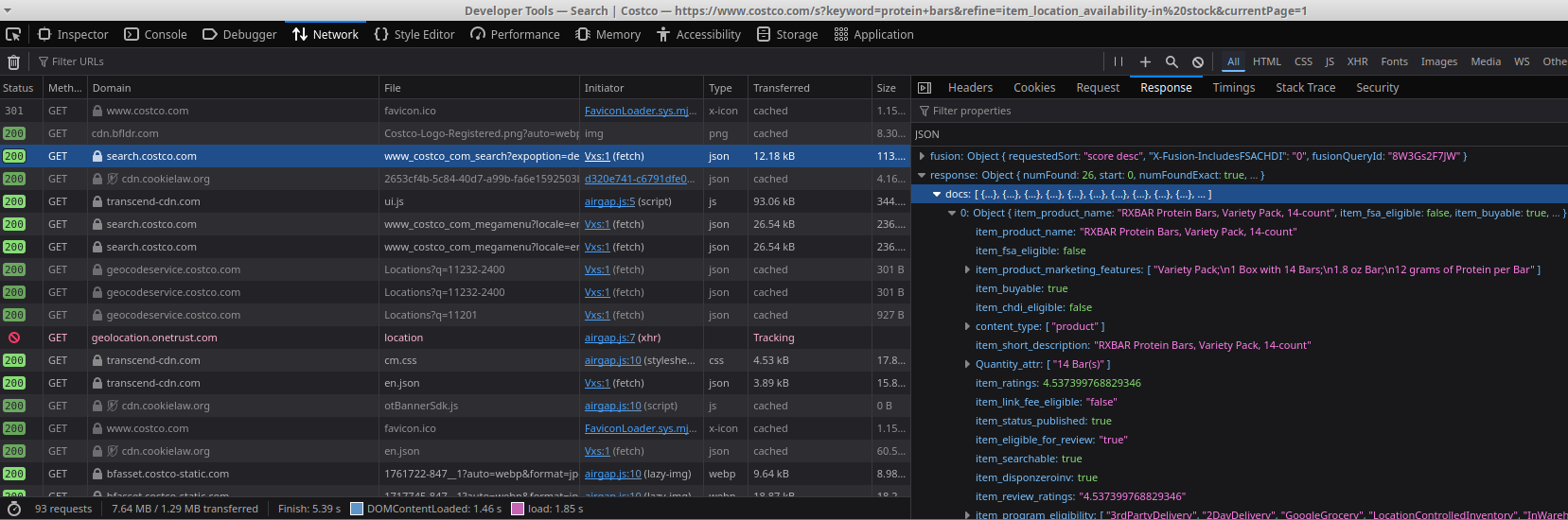
Now the question is how do I trigger it from the command line or Python. I tried with wget and curl to no avail - I still got timed out. The only thing that I thought was missing could be cookies so recovered them using Python's library browser_cookie3 and provided them to the request and... Bingo! response.status_code was 200 and the data was the same JSON we had in the Developer Tools.
import urllib3
import browser_cookie3
cookies = browser_cookie3.firefox(domain_name="costco.com")
url = "https://search.costco.com/api/apps/www_costco_com/query/www_costco_com_search"
params = {
"q": "protein bars",
...
}
headers = {
"Host": "search.costco.com",
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:135.0) Gecko/20100101 Firefox/135.0",
...
}
response = requests.get(url, headers=headers, params=params, cookies=cookies)
data = response.json()
Messing around with the parameters, I found that pagination is controlled by the start query parameter. This way, I was able to get all data items from all pages, which wasn't very difficult since there were only two pages. The next challenge was to find which key-value pairs were the ones I needed. I tried one combination of keys that worked for one item only to find that it didn't work for another. Instead of spending hours trying to find all the edge cases, I thought the easiest thing was to write up a LLM prompt and extract structured data from the JSON payload. LLMs are useful in extracting unstructured data so this messy JSON was the perfect candidate for it.
{'fusion':
{'requestedSort': 'score desc',
...
'item_name': 'Power Crunch Protein Energy Bar, French Vanilla, 1.4 oz, 12-count',
...
'item_review_ratings': '4.366700172424316',
...
'item_number': '1175308',
...
'Quantity_attr': ['12 Bar(s)'],
...
'item_location_pricing_pricePerUnit_price': 17.99,
...
'item_ratings': 4.366700172424316,
...
'item_location_pricing_listPrice': 17.99,
...
}
I quickly tested out 7 versions of a prompt and I stopped at this one. I combined it with a Pydantic schema for the response. This way, I don't have to worry about the data not following the structure I wanted. All the items were processed and written to disk for later processing. I usually prototype in Jupyter notebooks and I hate losing data due to a variable overwrite and having to redo all the queries. They cost money after all.
from openai import OpenAI
from pydantic import BaseModel, conlist
from typing import List, Tuple
from pathlib import Path
import json
client = OpenAI(api_key=key)
prompt = """
Give me the
item id
brand name of the product
how many bars are there per box
how many boxes are there per item
how much protein there is each bar
item rating
overall price
Do not hallucinate new information. Do not return any additional commentary.
"""
class Row(BaseModel):
product_id: str
brand_name: str
bars_per_box: int
boxes_per_item: int
protein_amount: int
item_rating: float
total_price: float
def to_dict(self):
return {
'product_id': self.product_id,
'brand_name': self.brand_name,
'bars_per_box': self.bars_per_box,
'boxes_per_item': self.boxes_per_item,
'protein_amount': self.protein_amount,
'item_rating': self.item_rating,
'total_price': self.total_price
}
for item_raw in data_items:
item = json.dumps(item_raw)
response = client.beta.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": item},
],
response_format=Row,
)
row_item = response.choices[0].message.parsed
processed_row_item = row_item.model_dump()
product_id = processed_row_item['product_id']
filename = save_dir / f"{product_id}.json"
filename.write_text(json.dumps(processed_row_item))
I was curious how to process the JSON via the command line so I looked up some utilities and I found jq which is just the right cmd tool for processing JSON. I still don't fully understand its query syntax but I learned enough to get the job done. I got the column names from the key values and I wrote them to the head of a CSV file. Afterwards, I processed each JSON file and I appended the results to the CSV file.
# write the column names to the top of the CSV file
jq -r 'keys_unsorted | @csv' ./costco_scrapes_v2/965181.json > costco_protein_bars_v2.csv
# iterate through JSON files and append the values in the specified key order to the CSV file
for file in ./costco_scrapes_v2/*.json; do
jq -r '[.product_id, .brand_name, .bars_per_box, .boxes_per_item, .protein_amount, .item_rating, .total_price] | @csv' "$file" >> costco_protein_bars_v2.csv;
done
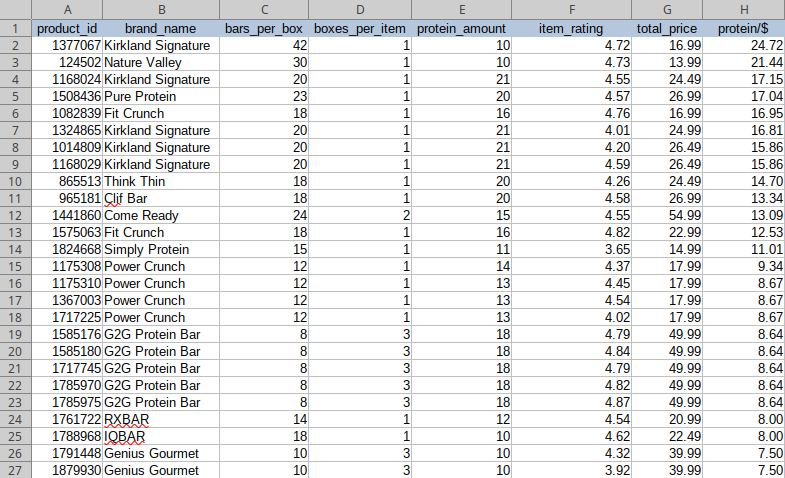
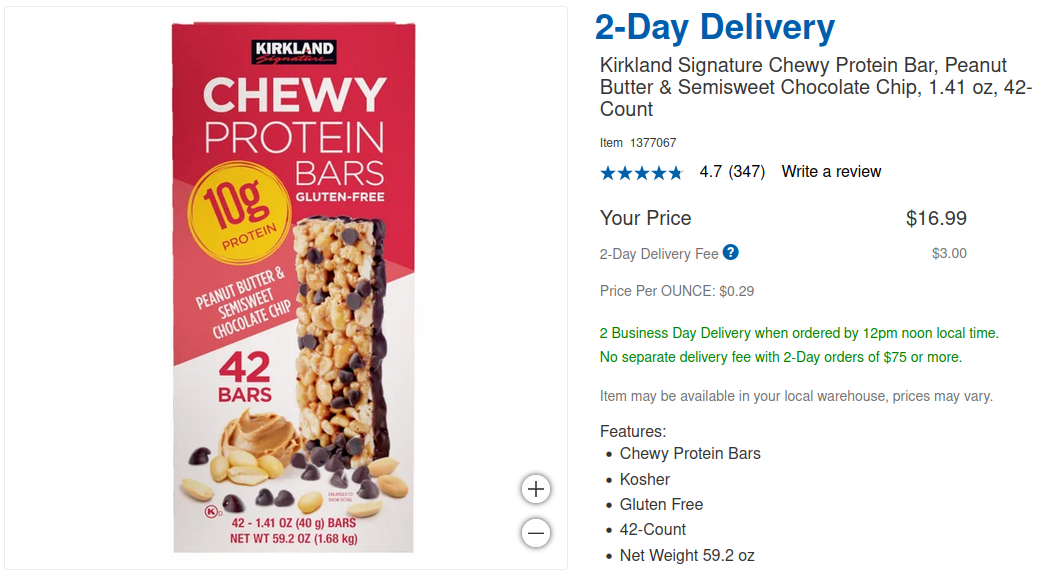
The final part of this exercise is to write some Excel magic to find the answer to the question: "What is the best protein bar deal at Costco?". I fired up LibreOffice, added a column with the formula = C:C * D:D * E:E / G:G, formatted everything nicely and sorted by the new column, descending. And we finally have an answer: Kirkland Signature with the big box of 42 bars with 10g of protein each is the best bang for your buck. Stay shredded, folks!